linkage
Árbol aglomerativo de grupos jerárquicos
Sintaxis
Descripción
Ejemplos
Agrupar datos y representar el resultado
Genere de forma aleatoria datos de muestra con 20.000 observaciones.
rng('default') % For reproducibility X = rand(20000,3);
Cree un árbol de grupos jerárquicos con el método de enlace ward. En este caso, la opción 'SaveMemory' de la función clusterdata se establece en 'on' de forma predeterminada. En general, especifique el mejor valor para 'SaveMemory' en función de las dimensiones de X y de la memoria disponible.
Z = linkage(X,'ward');Agrupe los datos en un máximo de cuatro grupos y represente el resultado.
c = cluster(Z,'Maxclust',4);
scatter3(X(:,1),X(:,2),X(:,3),10,c)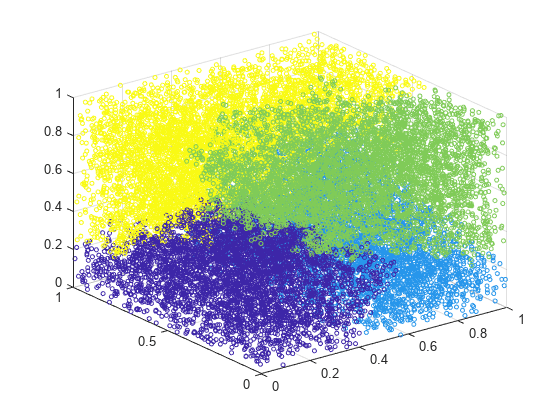
cluster identifica cuatro grupos de los datos.
Comparar asignaciones de grupos con clases
Encuentre un máximo de tres grupos en el conjunto de datos fisheriris y compare las asignaciones de grupos de las flores con su clasificación conocida.
Cargue los datos de muestra.
load fisheririsCree un árbol de grupos jerárquicos con el método 'average' y la métrica 'chebychev'.
Z = linkage(meas,'average','chebychev');
Encuentre un máximo de tres grupos en los datos.
T = cluster(Z,'maxclust',3);Cree un dendrograma de Z. Para ver los tres grupos, utilice 'ColorThreshold' con un corte a medio camino entre el antepenúltimo y el penúltimo enlace.
cutoff = median([Z(end-2,3) Z(end-1,3)]);
dendrogram(Z,'ColorThreshold',cutoff)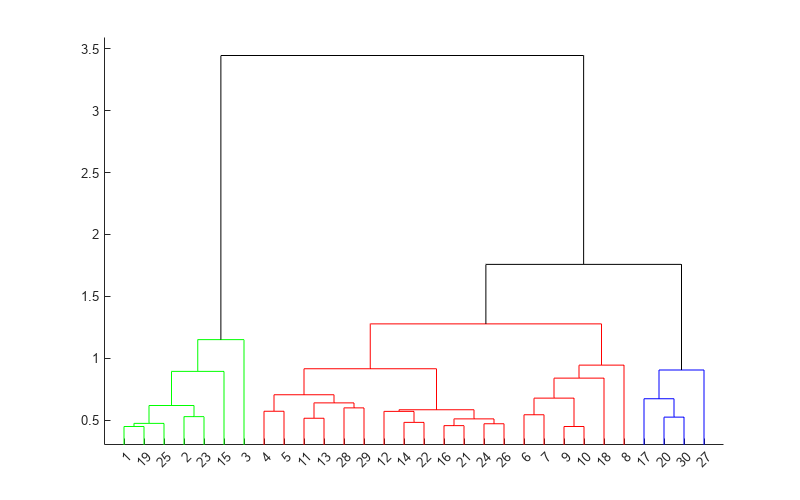
Muestre las dos últimas filas de Z para ver cómo se combinan los tres grupos en uno. linkage combina el grupo 293 (azul) con el grupo 297 (rojo) para formar el grupo 298 con un enlace de 1.7583. linkage combina entonces el grupo 296 (verde) con el grupo 298.
lastTwo = Z(end-1:end,:)
lastTwo = 2×3
293.0000 297.0000 1.7583
296.0000 298.0000 3.4445
Compruebe cómo las asignaciones de los grupos corresponden a las tres especies. Por ejemplo, uno de los grupos contiene 50 flores de la segunda especie y 40 flores de la tercera especie.
crosstab(T,species)
ans = 3×3
0 0 10
0 50 40
50 0 0
Observar el paso de agrupamiento en un árbol jerárquico
Cargue el conjunto de datos examgrades.
load examgradesCree un árbol jerárquico utilizando linkage. Utilice el método 'single' y la métrica de Minkowski con un exponente de 3.
Z = linkage(grades,'single',{'minkowski',3});
Observe el 25.º paso de agrupamiento.
Z(25,:)
ans = 1×3
86.0000 137.0000 4.5307
linkage combina la 86.ª observación y el 137.º grupo para formar un grupo de índice , donde 120 es el número total de observaciones en grades y 25 es el número de fila en Z. La distancia más corta entre la 86.ª observación y cualquiera de los puntos del 137.º grupo es 4.5307.
Agrupar datos mediante una matriz de diferenciación
Cree un árbol aglomerativo de grupos jerárquicos mediante una matriz de diferenciación.
Tome una matriz de diferenciación X y conviértala a una forma de vector que linkage acepte utilizando squareform.
X = [0 1 2 3; 1 0 4 5; 2 4 0 6; 3 5 6 0]; y = squareform(X);
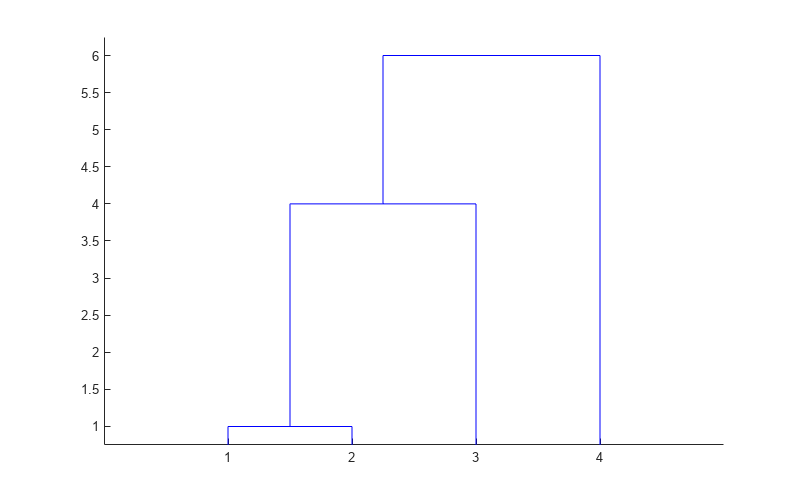
Cree un árbol de grupos utilizando linkage con el método 'complete' para calcular la distancia entre grupos. Las primeras dos columnas de Z muestran cómo linkage combina los grupos. La tercera columna de Z proporciona la distancia entre grupos.
Z = linkage(y,'complete')Z = 3×3
1 2 1
3 5 4
4 6 6
Cree un dendrograma de Z. El eje x corresponde a los nodos hoja del árbol y el eje y corresponde a las distancias de enlace entre grupos.
dendrogram(Z)
Argumentos de entrada
Argumentos de salida
Más acerca de
Sugerencias
El cálculo de
linkage(y)puede ser lento cuandoyes una representación de vector de la matriz de distancia. Para los métodos'centroid','median'y'ward',linkagecomprueba siyes una distancia euclidiana. Evite esta larga comprobación pasandoXen lugar dey.Los métodos
'centroid'y'median'pueden producir un árbol de grupos que no sea monótono. Este resultado se obtiene cuando la distancia desde la unión de dos grupos, r y s, a un tercer grupo es menor que la distancia entre r y s. En este caso, en un dendrograma diseñado con la orientación predeterminada, la ruta de una hoja al nodo raíz toma algunos pasos hacia abajo. Para evitar este resultado, utilice otro método. Esta figura muestra un árbol de grupos no monótono.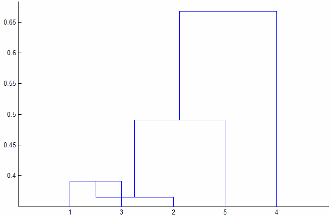
En este caso, el grupo 1 y el grupo 3 se unen formando un grupo nuevo y la distancia entre este grupo nuevo y el grupo 2 es menor que la distancia entre el grupo 1 y el grupo 3. El resultado es un árbol no monótono.
Puede proporcionar la salida
Za otras funciones incluyendodendrogrampara mostrar el árbol,clusterpara asignar puntos a los grupos,inconsistentpara calcular medidas inconsistentes ycophenetpara calcular el coeficiente de correlación cofenética.
Historial de versiones
Introducido antes de R2006a
Consulte también
cluster | clusterdata | cophenet | dendrogram | inconsistent | kmeans | pdist | silhouette | squareform
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)