Fit Kernel Distribution Object to Data
This example shows how to fit a kernel probability distribution object to sample data.
Step 1. Load sample data.
Load the sample data.
load carsmall;This data contains miles per gallon (MPG) measurements for different makes and models of cars, grouped by country of origin (Origin), model year (Year), and other vehicle characteristics.
Step 2. Fit a kernel distribution object.
Use fitdist to fit a kernel probability distribution object to the miles per gallon (MPG) data for all makes of cars.
pd = fitdist(MPG,'Kernel')pd =
KernelDistribution
Kernel = normal
Bandwidth = 4.11428
Support = unbounded
This creates a prob.KernelDistribution object. By default, fitdist uses a normal kernel smoothing function and chooses an optimal bandwidth for estimating normal densities, unless you specify otherwise. You can access information about the fit and perform further calculations using the related object functions.
Step 3. Compute descriptive statistics.
Compute the mean, median, and standard deviation of the fitted kernel distribution.
m = mean(pd)
m = 23.7181
med = median(pd)
med = 23.4841
s = std(pd)
s = 8.9896
Step 4. Compute and plot the pdf.
Compute and plot the pdf of the fitted kernel distribution.
figure x = 0:1:60; y = pdf(pd,x); plot(x,y,'LineWidth',2) title('Miles per Gallon') xlabel('MPG')
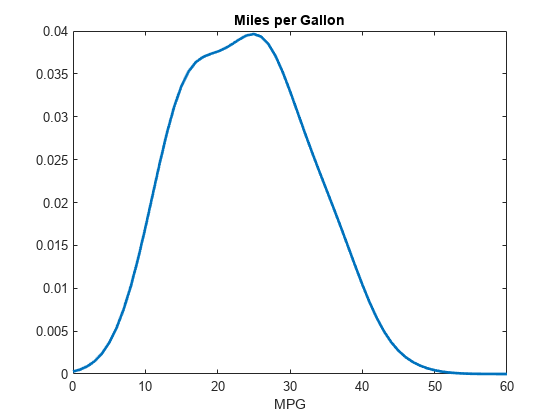
The plot shows the pdf of the kernel distribution fit to the MPG data across all makes of cars. The distribution is smooth and fairly symmetrical, although it is slightly skewed with a heavier right tail.
Step 5. Generate random numbers.
Generate a vector of random numbers from the fitted kernel distribution.
rng('default') % For reproducibility r = random(pd,1000,1); figure hist(r); set(get(gca,'Children'),'FaceColor',[.8 .8 1]); hold on y = y*5000; % Scale pdf to overlay on histogram plot(x,y,'LineWidth',2) title('Random Numbers Generated From Distribution') hold off
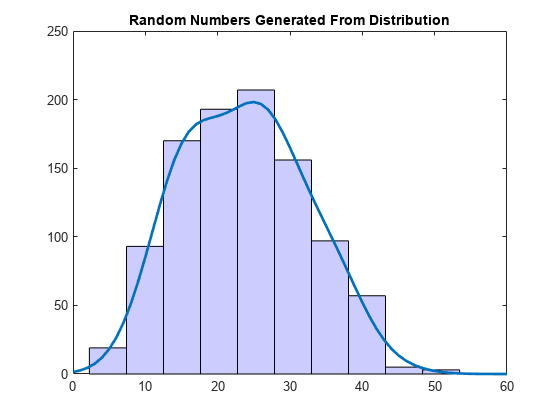
The histogram has a similar shape to the pdf plot because the random numbers generate from the nonparametric kernel distribution fit to the sample data.
See Also
fitdist | ksdensity | KernelDistribution
Related Topics
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)