classify
Clasificar observaciones mediante análisis discriminante
Sintaxis
Descripción
Nota
Se recomienda utilizar fitcdiscr y predict en lugar de classify para entrenar un clasificador de análisis discriminante y predecir etiquetas. fitcdiscr admite la validación cruzada y la optimización de hiperparámetros, y no requiere que ajuste el clasificador cada vez que haga una nueva predicción o cambie las probabilidades a priori.
class = classify(sample,training,group)sample en uno de los grupos a los que pertenecen los datos de training. Los grupos de training se especifican mediante group. La función devuelve class, que contiene los grupos asignados para cada fila de sample.
[ también devuelve la tasa de error aparente (class,err,posterior,logp,coeff] = classify(___)err), las probabilidades a posteriori de las observaciones de entrenamiento (posterior), el logaritmo de la densidad de probabilidad incondicional de las observaciones de muestra (logp) y los coeficientes de las curvas de límite (coeff), utilizando cualquiera de las combinaciones de argumentos de entrada de las sintaxis anteriores.
Ejemplos
Clasificación mediante análisis discriminante lineal
Cargue el conjunto de datos fisheriris. Cree group como un arreglo de celdas de vectores de caracteres que contenga las especies de iris.
load fisheriris
group = species;La matriz meas contiene cuatro medidas de pétalos de 150 iris. Realice una partición de manera aleatoria de las observaciones en un conjunto de entrenamiento (trainingData) y un conjunto de muestra (sampleData) con estratificación, utilizando la información de grupo de group. Especifique una muestra de retención del 40% para sampleData.
rng('default') % For reproducibility cv = cvpartition(group,'HoldOut',0.40); trainInds = training(cv); sampleInds = test(cv); trainingData = meas(trainInds,:); sampleData = meas(sampleInds,:);
Clasifique sampleData mediante análisis discriminante lineal y cree una gráfica de confusión a partir de las etiquetas verdaderas de group y las etiquetas predichas de class.
class = classify(sampleData,trainingData,group(trainInds)); cm = confusionchart(group(sampleInds),class);
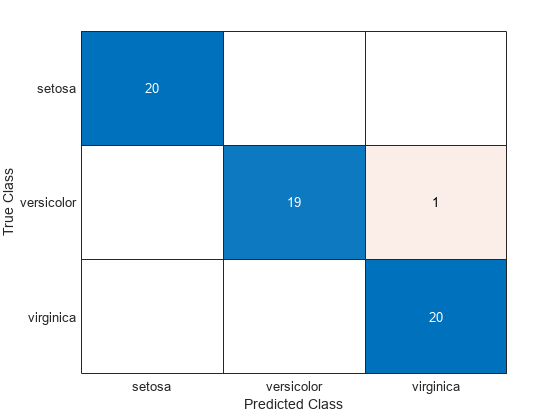
La función classify clasifica de forma errónea un iris versicolor como virginica en el conjunto de datos de muestra.
Realizar la clasificación mediante análisis discriminante cuadrático y visualizar el límite de decisión
Clasifique los puntos de datos de una cuadrícula de mediciones (datos de muestra) mediante el análisis discriminante cuadrático. A continuación, visualice los datos de muestra, los datos de entrenamiento y el límite de decisión.
Cargue el conjunto de datos fisheriris. Cree group como un arreglo de celdas de vectores de caracteres que contenga las especies de iris.
load fisheriris
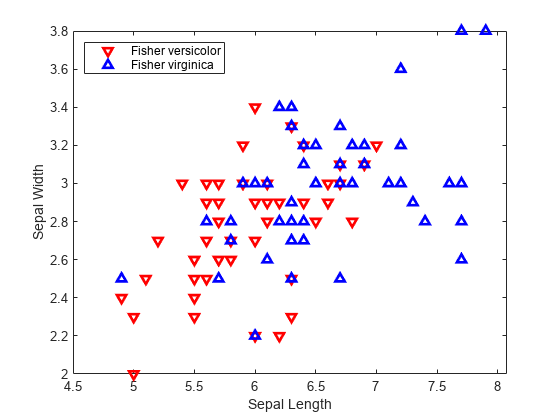
group = species(51:end);Represente las medidas de longitud (SL) y anchura (SW) de los sépalos de las especies iris versicolor y virginica.
SL = meas(51:end,1); SW = meas(51:end,2); h1 = gscatter(SL,SW,group,'rb','v^',[],'off'); h1(1).LineWidth = 2; h1(2).LineWidth = 2; legend('Fisher versicolor','Fisher virginica','Location','NW') xlabel('Sepal Length') ylabel('Sepal Width')
Cree sampleData como una matriz numérica que contenga una cuadrícula de medidas. Cree trainingData como una matriz numérica que contenga las medidas de longitud y anchura de los sépalos de las especies iris versicolor y virginica.
[X,Y] = meshgrid(linspace(4.5,8),linspace(2,4)); X = X(:); Y = Y(:); sampleData = [X Y]; trainingData = [SL SW];
Clasifique sampleData mediante un análisis discriminante cuadrático.
[C,err,posterior,logp,coeff] = classify(sampleData,trainingData,group,'quadratic');Recupere los coeficientes K, L y M para el límite cuadrático entre las dos clases.
K = coeff(1,2).const; L = coeff(1,2).linear; Q = coeff(1,2).quadratic;
La curva que separa las dos clases viene definida por esta ecuación:
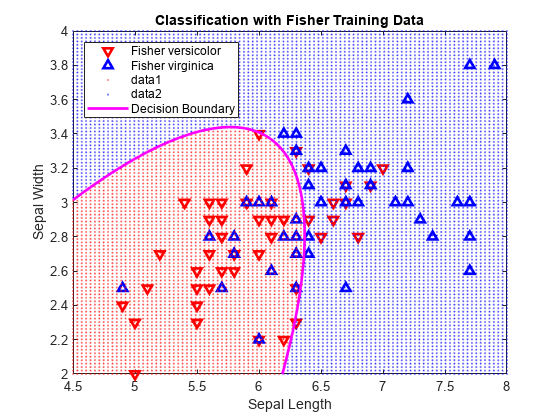
Visualice la clasificación discriminante.
hold on h2 = gscatter(X,Y,C,'rb','.',1,'off'); f = @(x,y) K + L(1)*x + L(2)*y + Q(1,1)*x.*x + (Q(1,2)+Q(2,1))*x.*y + Q(2,2)*y.*y; h3 = fimplicit(f,[4.5 8 2 4]); h3.Color = 'm'; h3.LineWidth = 2; h3.DisplayName = 'Decision Boundary'; hold off axis tight xlabel('Sepal Length') ylabel('Sepal Width') title('Classification with Fisher Training Data')
Visualizar los límites de clasificación del análisis discriminante lineal
Realice una partición de un conjunto de datos en datos de muestra y datos de entrenamiento y clasifique los primeros mediante un análisis discriminante lineal. A continuación, visualice los límites de la decisión.
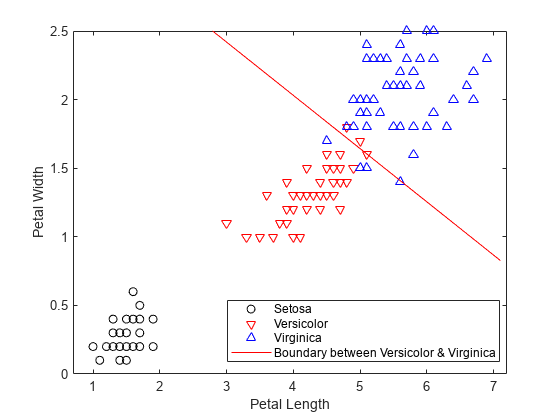
Cargue el conjunto de datos fisheriris. Cree group como un arreglo de celdas de vectores de caracteres que contenga las especies de iris. Cree PL y PW como vectores numéricos que contengan las medidas de longitud y anchura de los pétalos, respectivamente.
load fisheriris
group = species;
PL = meas(:,3);
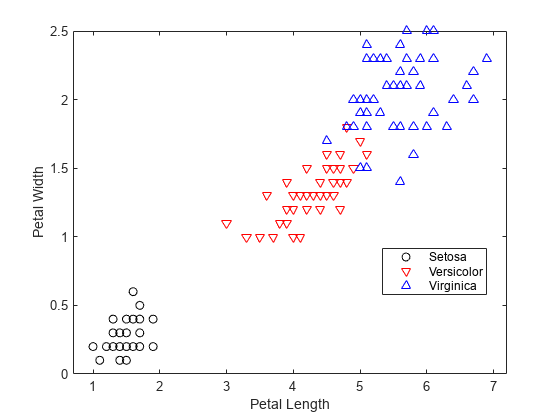
PW = meas(:,4);Represente las medidas de longitud (PL) y anchura (PW) de los sépalos de las especies iris setosa, versicolor y virginica.
h1 = gscatter(PL,PW,species,'krb','ov^',[],'off'); legend('Setosa','Versicolor','Virginica','Location','best') xlabel('Petal Length') ylabel('Petal Width')
Realice una partición de manera aleatoria de las observaciones en un conjunto de entrenamiento (trainingData) y un conjunto de muestra (sampleData) con estratificación, utilizando la información de grupo de group. Especifique una muestra de retención del 10% para sampleData.
rng('default') % For reproducibility cv = cvpartition(group,'HoldOut',0.10); trainInds = training(cv); sampleInds = test(cv); trainingData = [PL(trainInds) PW(trainInds)]; sampleData = [PL(sampleInds) PW(sampleInds)];
Clasifique sampleData mediante análisis discriminante lineal.
[class,err,posterior,logp,coeff] = classify(sampleData,trainingData,group(trainInds));
Recupere los coeficientes K y L para el límite lineal entre la segunda y la tercera clase.
K = coeff(2,3).const; L = coeff(2,3).linear;
La línea que separa la segunda y la tercera clase viene definida por la ecuación . Represente la línea límite entre la segunda y la tercera clase.
f = @(x1,x2) K + L(1)*x1 + L(2)*x2; hold on h2 = fimplicit(f,[.9 7.1 0 2.5]); h2.Color = 'r'; h2.DisplayName = 'Boundary between Versicolor & Virginica';
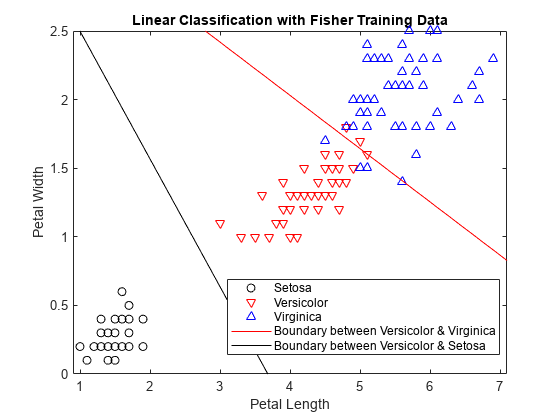
Recupere los coeficientes K y L para el límite lineal entre la primera y la segunda clase.
K = coeff(1,2).const; L = coeff(1,2).linear;
Represente la línea que separa la primera y la segunda clase.
f = @(x1,x2) K + L(1)*x1 + L(2)*x2; h3 = fimplicit(f,[.9 7.1 0 2.5]); hold off h3.Color = 'k'; h3.DisplayName = 'Boundary between Versicolor & Setosa'; axis tight title('Linear Classification with Fisher Training Data')
Argumentos de entrada
Argumentos de salida
Funcionalidad alternativa
La función fitcdiscr también realiza un análisis discriminante. Puede entrenar un clasificador con la función fitcdiscr y predecir las etiquetas de los nuevos datos con la función predict. La función fitcdiscr admite la validación cruzada y la optimización de hiperparámetros, y no requiere que ajuste el clasificador cada vez que haga una nueva predicción o cambie las probabilidades a priori.
Referencias
[1] Krzanowski, Wojtek. J. Principles of Multivariate Analysis: A User's Perspective. NY: Oxford University Press, 1988.
[2] Seber, George A. F. Multivariate Observations. NJ: John Wiley & Sons, Inc., 1984.
Historial de versiones
Introducido antes de R2006a
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)