Regresión lineal
Introducción
Un modelo de datos describe explícitamente una relación entre las variables predictivas y las variables de respuesta. La regresión lineal ajusta un modelo de datos que es lineal en los coeficientes del modelo. El tipo más común de regresión lineal es un ajuste de mínimos cuadrados, que puede ajustar tanto a las líneas como a los polinomios, entre otros modelos lineales.
Antes de modelizar la relación entre pares de cantidades, conviene realizar un análisis de correlación para saber si hay una relación lineal entre estas cantidades. Tenga en cuenta que las variables pueden tener relaciones no lineales que el análisis de correlación no puede detectar. Para obtener más información, consulte Correlación lineal.
La interfaz de usuario de ajuste básico de MATLAB® le permite ajustar sus datos, de modo que puede calcular los coeficientes del modelo y representar el modelo en la parte superior de los datos. Para ver un ejemplo, consulte Ejemplo: Usar la interfaz de usuario de ajuste básico. También puede utilizar las funciones de MATLAB polyfit y polyval para ajustar sus datos a un modelo lineal en los coeficientes. Para ver un ejemplo, consulte Ajuste programático.
Si necesita ajustar los datos con un modelo no lineal, transforme las variables para que la relación sea lineal. Alternativamente, intente ajustar una función no lineal directamente con la función Statistics and Machine Learning Toolbox™ nlinfit, con la función Optimization Toolbox™ lsqcurvefit o aplicando las funciones en Curve Fitting Toolbox™.
En este tema se explica cómo:
Realizar una regresión lineal simple con el operador
\.Utilizar el análisis de correlación para determinar si dos cantidades están relacionadas para justificar el ajuste de los datos.
Ajustar un modelo lineal a los datos.
Evaluar la bondad del ajuste representando valores residuales y buscando patrones.
Calcular las medidas de bondad del ajuste R2 y R2 ajustado
Regresión lineal simple
En este ejemplo se muestra cómo realizar una regresión lineal simple con el conjunto de datos accidents. En el ejemplo también se muestra cómo calcular el coeficiente de determinación para evaluar las regresiones. El conjunto de datos accidents contiene datos sobre accidentes de tráfico mortales en estados de Estados Unidos.
La regresión lineal modeliza la relación entre una variable dependiente o de respuesta y una o más variables independientes o predictivas. La regresión lineal simple solo considera una variable independiente mediante la relación
en la que es la intersección en y, es la pendiente (o coeficiente de regresión) y es el término de error.
Comience con un conjunto de valores observados de de y dados por , , ..., . Al utilizar la relación de regresión lineal simple, estos valores forman un sistema de ecuaciones lineales. Represente estas ecuaciones en forma de matriz como
Deje
La relación es ahora .
En MATLAB, puede encontrar usando el operador mldivide como B = X\Y.
A partir del conjunto de datos accidents, cargue los datos de accidentes en y y los datos de población de estado en x. Encuentre la relación de regresión lineal entre los accidentes ocurridos en un estado y la población de un estado mediante el operador \. El operador \ realiza una regresión de mínimos cuadrados.
load accidents x = hwydata(:,14); %Population of states y = hwydata(:,4); %Accidents per state format long b1 = x\y
b1 =
1.372716735564871e-04
b1 es la pendiente o el coeficiente de regresión. La relación lineal es .
Calcule los accidentes por estado yCalc de x utilizando la relación. Visualice la regresión representando los valores reales y y los valores calculados yCalc.
yCalc1 = b1*x; scatter(x,y) hold on plot(x,yCalc1) xlabel('Population of state') ylabel('Fatal traffic accidents per state') title('Linear Regression Relation Between Accidents & Population') grid on
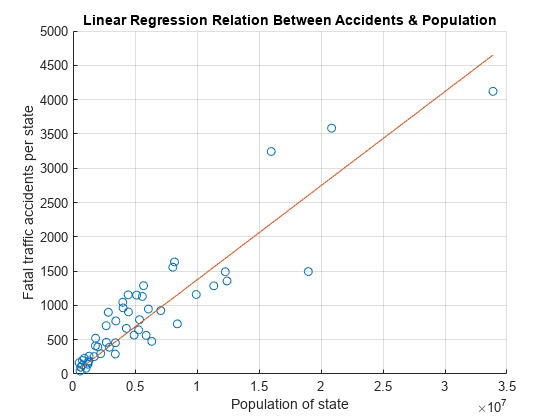
Mejore el ajuste mediante la inclusión de una intersección en y en su modelo como . Calcule rellenando x con una columna de unos y utilizando el operador \.
X = [ones(length(x),1) x]; b = X\y
b = 2×1
102 ×
1.427120171726538
0.000001256394274
Este resultado representa la relación .
Visualice la relación representándola en la misma figura.
yCalc2 = X*b; plot(x,yCalc2,'--') legend('Data','Slope','Slope & Intercept','Location','best');
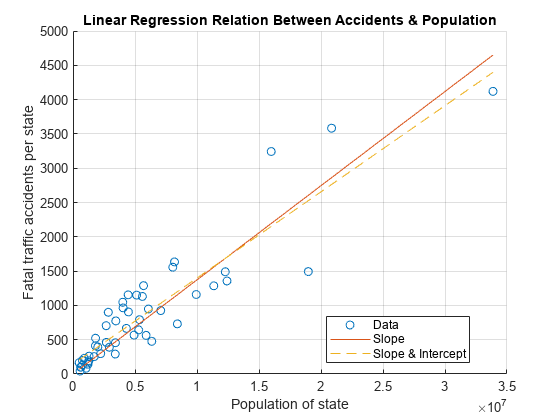
En la figura, los dos ajustes tienen un aspecto similar. Un método para encontrar el mejor ajuste es calcular el coeficiente de determinación, . es una medida de lo bien que puede predecir un modelo los datos y se sitúa entre y . Cuanto mayor sea el valor de , mejor será el modelo para predecir los datos.
Donde representa los valores calculados de y es la media de se define como
Encuentre el mejor ajuste de los dos ajustes comparando los valores de . Como muestran los valores , el segundo ajuste que incluye una intercepción en y es mejor.
Rsq1 = 1 - sum((y - yCalc1).^2)/sum((y - mean(y)).^2)
Rsq1 = 0.822235650485566
Rsq2 = 1 - sum((y - yCalc2).^2)/sum((y - mean(y)).^2)
Rsq2 = 0.838210531103428
Valores residuales y bondad del ajuste
Los valores residuales son la diferencia entre los valores observados de la variable (dependiente) de respuesta y los valores que un modelo predice. Cuando ajusta un modelo adecuado para sus datos, los valores residuales se aproximan a errores aleatorios independientes. Es decir, la distribución de los valores residuales no debe mostrar un patrón discernible.
La producción de un ajuste utilizando un modelo lineal requiere minimizar la suma de los cuadrados de los valores residuales. Esta minimización produce lo que se llama un ajuste de mínimos cuadrados. Puede obtener información sobre la "bondad" de un ajuste examinando visualmente una gráfica de los valores residuales. Si la gráfica residual tiene un patrón (es decir, los puntos de datos residuales no parecen tener una dispersión aleatoria), la aleatoriedad indica que el modelo no ajusta correctamente los datos.
Evalúe cada ajuste que realice en el contexto de sus datos. Por ejemplo, si su objetivo de ajustar los datos es extraer coeficientes que tengan significado físico, es importante que el modelo refleje la física de los datos. Comprender lo que representan sus datos, cómo se midieron y cómo se modelizan es importante al evaluar la bondad del ajuste.
Una medida de bondad de ajuste es el coeficiente de determinación o R2 (pronunciado R al cuadrado). Esta estadística indica la precisión con la que los valores que obtiene al ajustar un modelo coinciden con la variable dependiente que el modelo está destinado a predecir. Los estadísticos a menudo definen R2 utilizando la varianza residual de un modelo ajustado:
R2 = 1 – SSresid/SStotal
SSresid es la suma de los valores residuales al cuadrado de la regresión. SStotal es la suma de las diferencias cuadradas a partir de la media de la variable dependiente (suma total de cuadrados). Ambos son escalares positivos.
Para obtener información sobre cómo calcular R2 cuando utilice la herramienta de ajuste básico, consulte R2, el coeficiente de determinación. Para obtener más información sobre el cálculo de la estadística de R2 y su generalización multivariada, siga leyendo.
Ejemplo: Calcular R2 a partir del ajuste polinomial
Puede derivar R2 de los coeficientes de una regresión polinomial para determinar cuánta varianza en y explica un modelo lineal, como se describe en el ejemplo siguiente:
Cree dos variables,
xey, a partir de las dos primeras columnas de la variablecounten el archivo de datoscount.dat:load count.dat x = count(:,1); y = count(:,2);
Utilice
polyfitpara calcular una regresión lineal que prediceya partir dex:p = polyfit(x,y,1) p = 1.5229 -2.1911p(1)es la pendiente yp(2)es el intercepto del predictor lineal. También puede obtener coeficientes de regresión utilizando la interfaz de usuario de ajuste básico.Llame a la función
polyvalpara usarppara predecirynombrando al resultadoyfit:yfit = polyval(p,x);
El uso de
polyvalle ahorra escribir la ecuación de ajuste, que en este caso tiene este aspecto:yfit = p(1) * x + p(2);
Calcule los valores residuales como un vector de números enteros:
yresid = y - yfit;
Cuadre los valores residuales y súmelos para obtener la suma residual de cuadrados:
SSresid = sum(yresid.^2);
Calcule la suma total de cuadrados de
ymultiplicando la varianza deypor el número de observaciones menos1:SStotal = (length(y)-1) * var(y);
Calcule R2 utilizando la fórmula dada en la introducción de este tema:
Esto demuestra que la ecuación linealrsq = 1 - SSresid/SStotal rsq = 0.87071.5229 * x -2.1911predice el 87% de la variabley.
Calcular R2 ajustado para regresiones polinomiales
Por lo general, puede reducir los valores residuales en un modelo ajustando un polinomio de mayor grado. Cuando añade más términos, aumenta el coeficiente de determinación, R2. Obtiene un ajuste más cercano a los datos, pero a expensas de un modelo más complejo, para el que R2 no se puede tener en cuenta. Sin embargo, un refinamiento de esta estadística, R2 ajustado, incluye una penalización por el número de términos en un modelo. Por lo tanto, R2 ajustado es más adecuado para comparar cómo se ajustan los diferentes modelos a los mismos datos. El R2 ajustado se define como:
R2ajustado = 1 - (SSresid/SStotal)*((n-1)/(n-d-1))
En el ejemplo siguiente se repiten los pasos del ejemplo anterior, Ejemplo: Calcular R2 a partir del ajuste polinomial, pero se realiza un ajuste cúbico (grado 3) en lugar de un ajuste lineal (grado 1). A partir del ajuste cúbico, se calculan los valores simples y ajustados de R2 para evaluar si los términos adicionales mejoran la potencia predictiva:
Cree dos variables,
xey, a partir de las dos primeras columnas de la variablecounten el archivo de datoscount.dat:load count.dat x = count(:,1); y = count(:,2);
Llame a la función
polyfitpara generar un ajuste cúbico para predecirya partir dex:p = polyfit(x,y,3) p = -0.0003 0.0390 0.2233 6.2779
p(4)es el intercepto del predictor cúbico. También puede obtener coeficientes de regresión utilizando la interfaz de usuario de ajuste básico.Llame a la función
polyvalpara utilizar los coeficientes enppara predecirynombrando al resultadoyfit:yfit = polyval(p,x);
polyvalevalúa la ecuación explícita que puede introducir de forma manual como:yfit = p(1) * x.^3 + p(2) * x.^2 + p(3) * x + p(4);
Calcule los valores residuales como un vector de números enteros:
yresid = y - yfit;
Cuadre los valores residuales y súmelos para obtener la suma residual de cuadrados:
SSresid = sum(yresid.^2);
Calcule la suma total de cuadrados de
ymultiplicando la varianza deypor el número de observaciones menos1:SStotal = (length(y)-1) * var(y);
Calcule R2 simple para el ajuste cúbico utilizando la fórmula dada en la introducción de este tema:
rsq = 1 - SSresid/SStotal rsq = 0.9083Por último, calcule R2 ajustado para tener en cuenta los grados de libertad:
El R2 ajustado, 0,8945, es más pequeño que el R2 simple, 0,9083. Proporciona una estimación más fiable de la potencia de su modelo polinomial que se va a predecir.rsq_adj = 1 - SSresid/SStotal * (length(y)-1)/(length(y)-length(p)) rsq_adj = 0.8945
En muchos modelos de regresión polinomial, la adición de términos a la ecuación aumenta tanto R2 como R2 ajustado. En el ejemplo anterior, el uso de un ajuste cúbico aumentó ambas estadísticas en comparación con un ajuste lineal. (Puede calcular R2 ajustado para el ajuste lineal usted mismo para demostrar que tiene un valor más bajo). Sin embargo, no siempre es cierto que un ajuste lineal es peor que un ajuste de orden superior: un ajuste más complicado puede tener un R2 ajustado más bajo que un ajuste más simple, lo que indica que el aumento de la complejidad no está justificado. Además, mientras que el valor de R2 siempre varía entre 0 y 1 para los modelos de regresión polinomial que genera la herramienta de ajuste básico, el R2 ajustado para algunos modelos puede ser negativo, lo que indica que un modelo tiene demasiados términos.
La correlación no implica causalidad. Interprete siempre los coeficientes de correlación y determinación con cautela. Los coeficientes solo cuantifican la cantidad de varianza en una variable dependiente que elimina un modelo ajustado. Estas medidas no describen la pertinencia del modelo (o las variables independientes que seleccione) para explicar el comportamiento de la variable que predice el modelo.
Ajustar datos con las funciones Curve Fitting Toolbox
El software Curve Fitting Toolbox amplía la funcionalidad principal de MATLAB habilitando las siguientes capacidades de ajuste de datos:
Ajuste paramétrico lineal y no lineal, incluidos los mínimos cuadrados lineales estándar, los mínimos cuadrados no lineales, los mínimos cuadrados ponderados, los mínimos cuadrados restringidos y los procedimientos de ajuste robustos
Ajuste no paramétrico
Estadísticas para determinar la bondad del ajuste
Extrapolación, diferenciación e integración
Cuadro de diálogo que facilita la sección y el suavizado de datos
Guardar los resultados de ajuste en varios formatos, incluidos los archivos de código de MATLAB, los archivos MAT y las variables del área de trabajo
Para obtener más información, consulte la documentación de Curve Fitting Toolbox.
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)